In which Bob tries to figure out whether a paper by Persi Diaconis means ICM is wrong, and Uncle Tau explains that the question itself is a category error — ICM was never a utility, and neither is its replacement, and there’s a correction on top that nobody in the forum fight has heard of because it’s been sitting in the 1956 literature waiting for someone to compose two functions.
I wasn’t there for this one. Bob called me the next morning, still annoyed, with a photo of a napkin that had two bowls stacked on top of each other and the word GAUGE written underneath in Tau’s block capitals. I’m piecing the rest together from what he told me.
Bob had been reading a Diaconis paper. Not the coin-flipping one. The 2022 one, Gambler’s Ruin and the ICM, in Statistical Science. He’d gotten to the bit where Diaconis and Ethier show that for three players with stacks (1, 1, N−2), the ICM probability that the big stack busts first is about 600 times larger than what their gambler’s-ruin model predicts, and he’d closed the PDF and stared at his ceiling for about twenty minutes. Then he called Tau.
They met at the taquería. The el combo waiter appeared, said “el combo?”, Tau said “not today, amigo,” the waiter nodded like he does every week, and the conversation began.
Bob: So ICM is wrong.
Uncle Tau: ICM was never right.
Bob: That’s not an answer.
Uncle Tau: It’s the only answer. What did Diaconis and Ethier actually compute?
Bob: They computed the elimination probabilities under a different model. One where the game is a random walk — uniform pair selection, fair coin flips, one chip moves each round. They get different numbers than ICM. Really different. A factor of 600 at the short-stack corner.
Uncle Tau: Good. Now — and this is the question — is their model right?
Bob: I mean… it’s more principled than ICM, isn’t it? ICM just asserts Plackett-Luce with chip weights out of nowhere. Gambler’s ruin actually derives the probabilities from a transition rule.
Uncle Tau: From a transition rule. Uniform pair selection. One-chip bets. Fair coins. Have you ever in your life played a poker hand that was a one-chip bet with a uniformly-chosen opponent?
Bob: …No.
Uncle Tau: So they picked a different cartoon. ICM is one cartoon. Diaconis-Ethier is another cartoon. Neither cartoon is real poker. The question “which cartoon is right” is unanswerable, and it’s unanswerable structurally, not because we don’t have enough data.
Bob: The Fisher information thing from last time.
Uncle Tau: The Fisher information thing from last time. Your tournament results come through the same attenuated Markov chain whether the underlying model is ICM or DE or FGS or Ganzfried-Sandholm. The data doesn’t adjudicate. Diaconis says so himself at the end of his paper — he lists four models, says they disagree, says “we wouldn’t be surprised if all these models are inadequate.” He’s a probabilist who’s spent fifty years staring at these problems. If he’s hedging, it’s because he can see the same wall you can.
Bob: OK but then the question is — which cartoon do I use at the table?
Uncle Tau: Wrong question.
Bob: Uncle Tau. Come on.
Uncle Tau: No, listen. This is the part everyone on the forums gets wrong, and they get it wrong because they haven’t noticed a single specific thing that’s been sitting in plain sight since Kelly wrote his 1956 paper. Let me ask you: what is ICM?
Bob: ICM is… the concave utility of the tournament. It maps chips to dollars. It’s what you optimize.
Uncle Tau: Stop.
Tau had that expression. Bob describes it as the weight just got set down.
Uncle Tau: ICM is not a utility. ICM has never been a utility. ICM is a chips-to-dollars equity map. Those are different objects.
Bob: Aren’t they the same thing?
Uncle Tau: Tell me what a utility is.
Bob: A function that takes wealth and gives you… how much you want it.
Uncle Tau: Right. A utility takes wealth and tells you the player’s preference over wealth. Now what does ICM take as input?
Bob: Chips.
Uncle Tau: And what does it produce?
Bob: A dollar equity.
Uncle Tau: So ICM goes chips → dollars. That’s an equity map. It answers the question “what’s your fair share of the prize pool right now given your chip stack.” It does not answer the question “how much do you care about that fair share relative to your overall financial life.” Those are different questions.
Bob: OK but when we use ICM, we optimize it. We maximize expected ICM. Isn’t that treating it like a utility?
Uncle Tau: Yes. And that’s the error. When you maximize expected ICM, you are implicitly saying “my utility over dollars is linear.” You’re saying one more dollar of tournament equity is worth exactly one more dollar of utility, regardless of how much wealth I have, regardless of where that dollar lands, regardless of whether I’m playing a five-dollar tournament or a ten-thousand-dollar tournament. That’s a risk-neutrality assumption. And nobody is risk-neutral in dollars. Especially not on a buy-in that’s a meaningful fraction of their bankroll.
Bob: So ICM secretly assumes I’m risk-neutral in dollars.
Uncle Tau: ICM, used as a direct optimization target, secretly assumes you’re risk-neutral in dollars. That’s a different claim. ICM as a chips-to-dollars map is fine. It’s doing its job. The error is in what happens next, after the map, which every practitioner skips over so fast they don’t realize a step was skipped.
Bob: OK so walk me through it. What’s the skipped step?
Uncle Tau: The skipped step is the utility over wealth. ICM gives you a dollar number, M-of-chips. A full decision objective requires a utility over wealth — call it U. The real thing you’re maximizing is 𝔼[U(wealth)], and wealth is external bankroll plus tournament equity. So it’s
𝔼[ U(B + M(chips)) ]
where B is your bankroll outside the tournament, M(chips) is whatever chips-to-dollars map you’re using, and U is the utility over the total.
Bob: And U is…
Uncle Tau: U is log. By Kelly. That’s the whole of the 1956 result. For a finite-bankroll player maximizing long-run geometric growth, the utility over wealth is logarithmic.
Bob: Hold on. What if I’m not actually a Kelly guy. What if I’m more risk-averse than log, or I’m running fractional Kelly, or I just don’t buy the ergodicity argument at all.
Uncle Tau: Then you get a different concave outer and the argument doesn’t move an inch. Log is where Kelly-Breiman lands specifically. CRRA with any positive coefficient is concave. Fractional Kelly is a more-risk-averse concave deflator of log. A Bayesian average over your own uncertainty about how risk-averse you actually are — still concave. The load-bearing property of the outer layer isn’t “log.” It’s concavity.
Bob: So the sign of the correction survives.
Uncle Tau: Tighter than M, for every strictly concave outer. The magnitude depends on which concave shape you picked and on how big your stakes are relative to your bankroll. Log is the Kelly-canonical point. Fractional Kelly is the canonical practitioner’s deviation. CRRA is the textbook generalization. Every risk-averse human at the tournament is covered. The only agent that escapes the tightening is a literal risk-neutral one, and that agent doesn’t exist outside a textbook example.
Bob: So “use log” is a recommendation, not a theorem.
Uncle Tau: “Use some concave outer” is the theorem. “Use log specifically” is the Kelly-canonical instance of that theorem, plus the practical observation that most serious pros end up within a factor of one-half of log anyway, whether they call it that or not.
Bob: So the full utility is…
Uncle Tau: U = log(B + M(chips)). I’ll write log because it’s the clean default. But the theorem is about the shape of the outer, not its name. Any strictly concave choice gives the same composition and the same direction; only the magnitude moves.
He wrote it on a napkin. Bob says it took him about fifteen seconds to process.
Bob: Wait. The ICM part is inside a log.
Uncle Tau: The ICM part is inside a log.
Bob: So there’s two concavities stacked on top of each other.
Uncle Tau: Two concavities stacked on top of each other. One from M — because the prize structure is top-heavy, so chips compress into dollars on a curved surface. One from the log — because dollars compress into utility on a curved surface due to finite wealth. The composition is concave for two completely independent reasons. Jensen stacks. The optimal play is strictly tighter than what naked ICM tells you.
Bob: Hold on. Tighter?
Uncle Tau: Tighter.
Bob: But the whole forum says ICM is too tight. That you have to deviate looser to win tournaments.
Uncle Tau: The whole forum has the sign exactly backwards. And they have it backwards because they think ICM is the full utility, and therefore the “correction” must be in the looser direction to make up for ICM being “too conservative.” It’s not too conservative. It’s not conservative enough. It’s missing the outer log. The missing layer pushes everything tighter, not looser.
Bob: OK pause. This is the bit I want to make sure I have. You’re telling me the folk wisdom, the Ganzfried-Sandholm solvers, the Libratus crowd, the solvers on the coaching sites — all of them are arguing about whether to loosen or tighten from ICM, and the whole argument is on the wrong side of zero?
Uncle Tau: The whole argument is on the wrong side of zero relative to the true objective, which nobody writes down because nobody has noticed that ICM is the inner function. They write down ICM, they maximize it, they call corrections to ICM “utility corrections,” and they’ve never composed ICM with the actual utility over wealth. The composition is twice-concave, the Jensen penalty doubles, and the correct play is strictly tighter.
Bob: So if I use ICM at the table, I should be tighter than the ICM solver says.
Uncle Tau: Yes. How much tighter depends on your bankroll. Small spot in a big bankroll, the outer log is nearly linear, the extra tightening is small. Big spot in a small bankroll — final table, pay jump that’s a year of buy-ins — the outer log has serious curvature and the tightening is severe.
Bob: And this is why high-stakes pros always seem to play tighter at final tables than the sim says.
Uncle Tau: I’m not going to validate that with an empirical claim. The whole paper is about how we can’t verify empirical claims like that — the channel is closed. But the math says optimal play is tighter whenever B is finite. That stands on its own. It doesn’t need a vibe check from Instagram final-table content.
Bob: Right. OK. So back to my original question. Diaconis-Ethier. ICM. Which one?
Uncle Tau: Doesn’t matter.
Bob: Uncle Tau.
Uncle Tau: I mean it. Watch.
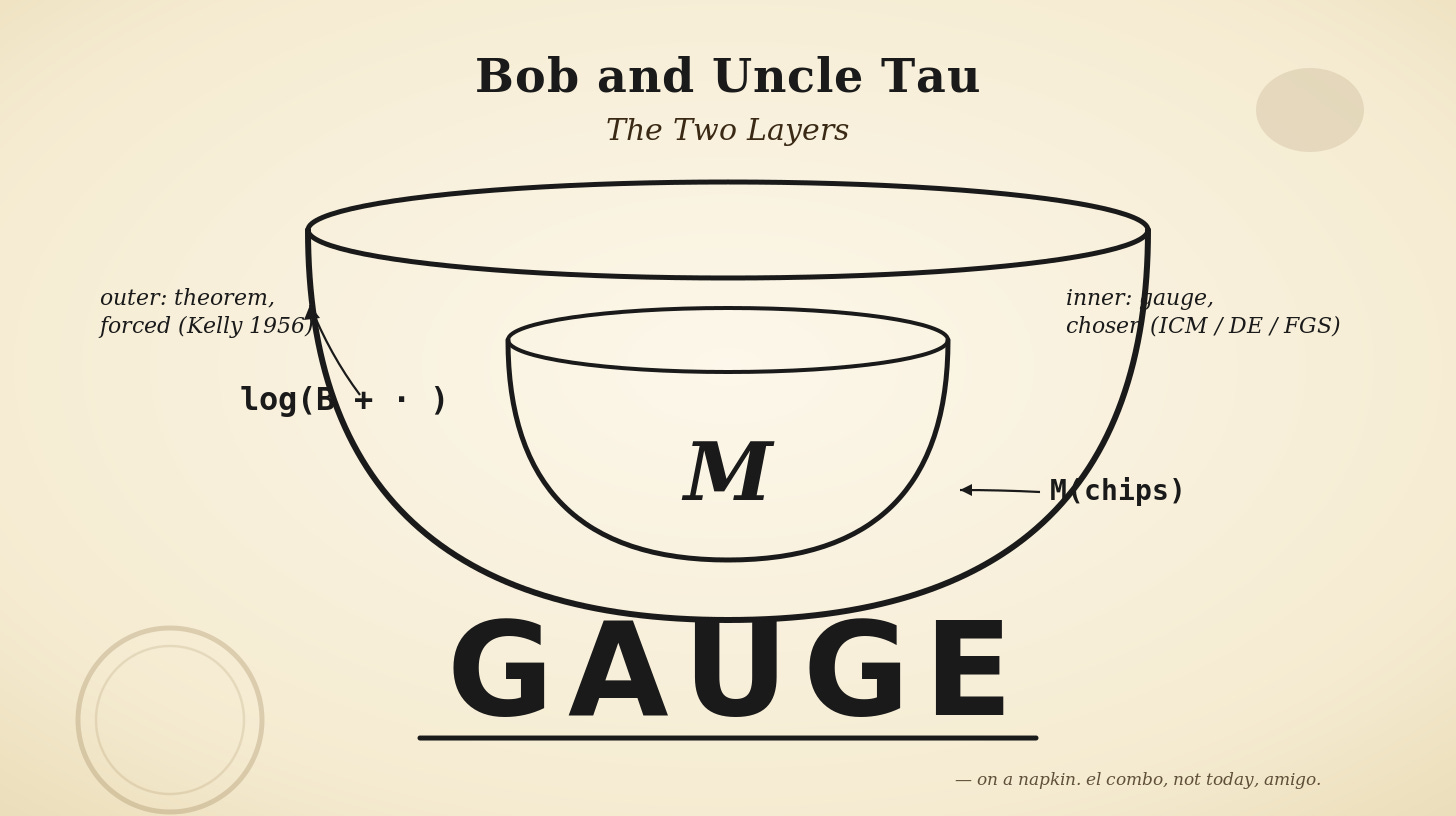
He drew two bowls on the napkin, nested. The inner bowl he labeled M. The outer bowl he labeled log(B + · ).
Uncle Tau: This is the object. The outer bowl is the Kelly layer. It doesn’t care what’s inside. You can plug in ICM. You can plug in Diaconis-Ethier. You can plug in FGS. You can plug in Ganzfried-Sandholm. You can plug in a Plackett-Luce with square-root weights if you’re feeling cute. Each one gives you a different inner M. All of them are members of the same family — structurally-computed, concave chips-to-dollars maps. None of them is a utility. All of them require the outer log layer to become a real decision objective.
Bob: So the inner is… a choice? A free parameter?
Uncle Tau: The inner is a gauge. And I want to slow down on that word because I keep throwing it around and you’re going to see it again. It means something specific and the forums don’t have a word for it, which is part of why they keep going in circles.
Bob: Fine. What’s a gauge.
Uncle Tau: Start with voltage. You put a probe on a wire and read 12 volts. Is 12 a fact about the universe?
Bob: …Probably?
Uncle Tau: It is not. Voltage is only defined relative to a reference point — ground, another terminal, whatever you picked. You can shift every voltage in the universe by plus five and not a single measurement anywhere changes. The only physical quantity is the difference between two voltages. The absolute number is bookkeeping. Physicists call that a gauge — a representational convention that has no observable consequences by itself.
Bob: OK.
Uncle Tau: Now here’s the key distinction. A parameter is a hidden number with a true value you could in principle measure. “How heavy is this book” — there’s an answer, go get a scale. A gauge is not that. A gauge is a choice of coordinate system. Two different choices are two different descriptions of the same underlying thing, and asking “which one is correct” is a confused question because there’s no fact of the matter at the level of the representation.
Bob: So it’s like…
Uncle Tau: Go on.
Bob: A street map versus a subway map. Same city, completely different-looking maps, they disagree about distances and angles, a subway map basically lies about geography on purpose, but they’re both valid because they’re optimizing for different things.
Uncle Tau: That’s exactly it. Neither map is the city. The city is the thing. Subway maps distort distance to make topology legible. Street maps preserve distance and lose topology. Topo maps preserve elevation and drop street names. None of them is “right,” because “right” isn’t a property that lives at the level of maps — it lives at the level of the city. The maps are representations. The city is invariant.
Bob: And the tournament is a city.
Uncle Tau: The tournament is the city. ICM is one map of it — the Plackett-Luce-on-chip-weights map. DE is another map — the unit-bet-random-walk map. FGS is a short-range-accurate map that goes fuzzy at distance. Ganzfried-Sandholm is a strategic-model map. Each one captures something the others distort. None of them is the tournament. They’re cartoons. Asking “which cartoon is right” is asking the subway-map-versus-street-map question, and the answer is still “it depends what you’re doing, and there’s no underlying fact that makes one of them The True Map.”
Bob: And the data can’t distinguish them because…
Uncle Tau: Because tournament outcomes are properties of the city, not of any particular map. The city is the same whichever map you hold. Even with infinite data — more data than will ever exist — you still wouldn’t be able to pick a “correct” map, because none of them is the city. That’s the gauge part: the ambiguity is structural, not a sample-size problem. And on top of that, the DPI wall from last time says even if the ambiguity were just a sample-size problem, your sample size isn’t getting there either. Two reasons for the same conclusion.
Bob: So “gauge” means: it’s a choice, and the thing measuring you can’t tell you which choice is right, and there might not even be a right one to tell.
Uncle Tau: Exactly that. A parameter lives inside the world and has a true value. A gauge lives inside the description of the world and doesn’t. Tournament-result data is a probe of the world. It can shrink the uncertainty on parameters, slowly. It cannot shrink the uncertainty on gauges, ever, because gauges are in the map, not the territory.
Bob: And the outer log —
Uncle Tau: Is not a gauge. The outer log is a theorem. Kelly 1956: if you want to maximize long-run geometric growth on a finite bankroll, log-of-wealth is the utility, full stop. Any other utility is dominated with probability one over infinite horizons. So when we compose the full objective, we’ve got two very different kinds of thing stacked on each other —
He wrote on the napkin:
U = log(B + · ) ∘ M(chips)
outer — theorem, forced inner — gauge, chosen
Uncle Tau: The inner is a map. You pick one. The outer is a theorem. You don’t pick it. The forums argue about the map and don’t know the theorem exists.
Bob: So when people argue about whether ICM or DE is “right,” they’re arguing about which subway map of Tokyo is “right.”
Uncle Tau: And they’re doing it while nobody has noticed that the real question — how tightly should I drive, given my actual car and my actual fuel tank — has a theorem attached to it from 1956 that they’ve never read.
Bob: Jesus.
Uncle Tau: I said it was depressing if you came in wanting to prove you were special.
Bob: OK so back on track. When the forums argue about whether ICM or DE is “right,” they’re arguing about a gauge.
Uncle Tau: They’re arguing about something the data can never resolve, and they don’t know the Kelly layer exists.
Bob: That’s a lot of words being typed for no reason.
Uncle Tau: Welcome to poker discourse.
Bob: But wait. DE and ICM give really different numbers in some spots. 600x at the short-stack corner. Fifty grand per seat at the 2019 WSOP chop. That’s not nothing.
Uncle Tau: It’s not nothing. It’s just not falsifiable. And the corrections don’t even push the same way as the outer log does — the two corrections are orthogonal.
Bob: Meaning?
Uncle Tau: Meaning at the short-stack corner, DE says ICM overestimates how often the big stack busts first. DE says “your short stack isn’t going to miracle through. You’re gonna blind out. Stop pretending the field will kill each other for you.” So relative to ICM, DE says: short stacks should play looser, not tighter.
Bob: Looser.
Uncle Tau: Looser. In that specific corner.
Bob: But you just said the outer log says tighter.
Uncle Tau: Always says tighter. Every state, every corner, every stack depth. The outer log is monotone — more concavity, more Jensen, tighter play.
Bob: So in the short-stack corner, DE says looser, Kelly says tighter, and the net depends on—
Uncle Tau: On your bankroll. Small bankroll, Kelly dominates, you play tight. Large bankroll, DE dominates, you play looser than ICM. In the middle of the simplex, DE is close to ICM and the Kelly layer dominates, net tighter. At the big-stack corner, DE says press more, Kelly says press less, net depends on size again.
Bob: So the correction is sign-varying.
Uncle Tau: The correction is a sign-varying field over the simplex. And that is why every forum argument of the form “the correction is worth X percent EV” is a category error twice over. Once because EV is the wrong currency — we care about growth rate, not EV — and once because the correction isn’t a scalar at all. It’s a field that changes sign. There’s no number. There’s a map.
Bob: OK let me try to say this back to you.
Uncle Tau: Go.
Bob: There’s a family of things that convert chips into dollars. ICM is one. Diaconis-Ethier is another. FGS is another. Ganzfried-Sandholm is another. I pick one based on whichever cartoon I think is closest to real poker — but I can’t verify that choice from tournament results, so it’s a judgment call, and I should be honest that it’s a judgment call.
Uncle Tau: Good.
Bob: Whichever one I pick, it’s not a utility. It’s a chips-to-dollars map. To turn it into a utility I have to put a log around it, with my real-life bankroll inside the log.
Uncle Tau: Good.
Bob: The log is not a choice. The log is forced by Kelly. It doesn’t care which inner I picked.
Uncle Tau: Good.
Bob: The composition — log of (B plus M of chips) — is twice concave. So the Jensen penalty doubles. So optimal play is tighter than whatever the inner model alone says.
Uncle Tau: Good.
Bob: And the “ICM is too tight” folks are fighting an argument on the wrong side of zero because they think the inner model is the full utility.
Uncle Tau: Good.
Bob: And the “ICM vs DE” folks are fighting an argument about a gauge that tournament data can never resolve.
Uncle Tau: Perfect.
Bob: So in practice, at the table, I should…
Uncle Tau: Use ICM because it’s the readout you have. Know that it’s a gauge. Play tighter than its output would suggest, proportional to how big the spot is relative to your bankroll. Stop arguing with people about which inner model is correct. Start paying attention to whether you’re doing the outer log at all, which nobody is.
Bob went quiet for a beat. Then a different expression — the one he gets when he thinks he’s caught Tau in something.
Bob: Wait. Hang on. I think I’ve got an out here.
Uncle Tau: Go.
Bob: If I Kelly-size before the tournament. If I use the log utility at the point of entering — I check that this buy-in is a small enough fraction of my bankroll that log-of-wealth is approximately linear over the range of outcomes I can hit. Then I’ve already paid the utility tax at the door. Pre-funded the risk. Once I’m sitting down, I can stop worrying about the outer log, treat the tournament as a local EV problem, and just maximize chip-EV. The nonlinearity is already priced in at entry. In the tournament: straight EV max. No more utility thinking.
He looked quite pleased with himself.
Uncle Tau: You’re starting to sound like the Accountant.
Bob: Oh fuck off.
Uncle Tau: No, listen. That argument has a real form, and the real form fails in three specific ways, and they’re all worth understanding. Here’s why that doesn’t work.
Uncle Tau: First one. The Kelly-at-entry argument says: “this buy-in is small enough relative to my bankroll that log(B + x) is approximately linear over the range of x I’ll see.” What’s the range of x you can see?
Bob: Zero to first place.
Uncle Tau: Right. Zero to first place. Now — in a top-heavy MTT — how big is first place relative to a typical buy-in?
Bob: In a 500-runner, maybe 100 to 200 buy-ins.
Uncle Tau: And what’s a properly Kelly-sized bankroll for entering a 500-runner MTT?
Bob: Depends on ROI. Maybe 200–400 buy-ins for a solid winner.
Uncle Tau: So the entry is 0.25% to 0.5% of your bankroll. But the top prize is 25% to 100% of your bankroll. Those are not the same range. The entry is small. The outcome distribution has a heavy tail that is not small. And log is not linear over 100% of your bankroll. It’s linear over 1% of your bankroll. It is decidedly not linear over 50%.
Bob: Oh.
Uncle Tau: Where does all the Fisher information about your skill live?
Bob: Top of the payout distribution.
Uncle Tau: And where does all the payout variance live?
Bob: Top of the payout distribution.
Uncle Tau: So the very outcomes that matter most — the deep runs, the wins, the big scores — are precisely the outcomes where the “log is locally linear” approximation breaks. The entry cost is small. The outcome distribution is not small. The whole point of the outer log is that it’s curved exactly where the action is. Kelly-sizing the buy-in doesn’t flatten the curve; it just guarantees that the expected value of the composed object is positive. Different thing.
Uncle Tau: Second one. Kelly at entry and Kelly in the tournament are solving two different problems.
Bob: Yeah?
Uncle Tau: Kelly at entry solves: “should I enter this tournament, and at what size relative to my bankroll?” That’s a budgeting question. It gives you a yes/no and a size. Kelly in the tournament solves: “given that I’m in, how do I play each spot so that my composed utility over the final outcome distribution is maximized?” That’s a strategic question. It gives you an action at every state.
Paying the utility tax at the door doesn’t answer the strategic question. It just says “you budgeted correctly.” You can budget correctly and then play badly within that budget. Budgeting and playing are separate. The Accountant’s whole worldview is that if the salary is set, you just show up and grind. That’s the additive thinking you’ve been trying not to do for a year.
Bob: …Yeah.
Uncle Tau: You don’t get to pre-fund strategy. You pre-fund exposure. Those aren’t the same.
Uncle Tau: Third one, and this is the one that closes it. Pre-funding at entry handles the mean. It does not handle variance.
Bob: Meaning?
Uncle Tau: Suppose you Kelly-sized your entry. Great. Now you’re at the table. Someone proposes a chip-EV-neutral deviation — a flip, a big spew, some line that doesn’t change your expected chip count but adds a bunch of variance to it. In chip-EV terms, that’s free. You said you’d maximize chip-EV in-tournament. So you take it. What happens to your growth rate?
Bob: …goes down.
Uncle Tau: By how much?
Bob: By the Jensen penalty on the composed utility.
Uncle Tau: Which is twice-concave. And which doesn’t care that you Kelly-sized at entry. The variance penalty exists whether or not you budgeted correctly. Pre-funding your exposure doesn’t purchase you indifference to variance. The whole reason the outer log is there is that it taxes variance independently of how big the bet is relative to your roll. You still pay the tax on every variance-adding deviation, because the composed utility is concave and variance is strictly taxed on concave utilities.
The slogan version: Kelly-at-entry handles “should I play?” — it does not handle “how should I play?”
Bob: Shit.
Uncle Tau: And then a fourth thing, which is less a mathematical point than a behavioral one.
Bob: Go on.
Uncle Tau: Most people who say “I Kelly-sized at entry so I’ll play EV-max in-tournament” are not actually Kelly-sized at entry. They just like the half of the argument that says they can EV-max. Kelly at entry means your ROI estimate is right, your variance estimate is right, and the ratio of those gives you a fraction of bankroll you should commit, and you committed that fraction. Almost nobody who cites this argument has actually run those numbers. They’ve run no numbers. They’ve just found a principled-sounding way to say “I want to gamble.” The EV-max play becomes a permission structure for spew.
Bob: That’s not the version of the argument I was making.
Uncle Tau: I know. But it’s the version 95% of the internet is actually making when they reach for it. I’m not accusing you. I’m telling you the shape of the error you almost fell into.
Bob opened his mouth to respond.
What happened next — the door slamming open, the man in the slightly-too-long overcoat, Richard Bellman’s 1953 fraud against the United States Congress, the discovery that the Reverend who wrote down Bayes’s rule was literally a priest, the fact that his grandfather’s recursion is running every solver you’ve ever paid for, the question of how many independent reasons the value function is actually hidden from us, and Bob’s polemic about why his tenth-grade geometry teacher owes him twenty years of lost shapes — is in Part 2.
References for Part 1: Persi Diaconis and Stewart Ethier (2022), “Gambler’s Ruin and the ICM,” Statistical Science 37(3):289–305. John Kelly Jr. (1956), “A New Interpretation of Information Rate,” Bell System Technical Journal 35:917–926. David Harville (1973), “Assigning Probabilities to the Outcomes of Multi-Entry Competitions,” JASA 68:312–316. John Pratt (1964), “Risk Aversion in the Small and in the Large,” Econometrica 32:122–136. Leo Breiman (1961), “Optimal gambling systems for favorable games,” Berkeley Symposium. The composition is ours, in the sense that composing two functions is anybody’s.
New essays in your inbox
Free Substack — subscribe to get new posts as they ship. No upsell.
About FelixD
Joined bitB Staking as an intern, left as CFO. Now founder of Mota GmbH.
Related essays
-
Bob and Uncle Tau: The Two Layers (Part 2 of 2) — More Floors
Previously in Part 1: Bob had been reading Diaconis-Ethier 2022 — the paper where ICM disagrees with gambler’s-ruin elimination probabilities by a factor of 600 at the short-stack corner — and called Uncle Tau in distress. At the back of the taquería he got a lecture about why “which model is right” is a category…
-
El Combo
Date: June 1, 2026 Location: Cell Block 4 (The “Tropical Purgatory”) Status: 116% Humidity. Sam is currently negotiating with a lizard for a better WiFi signal. Nokia 3310 battery: 0.1% (Potato battery is vibrating). Bob’s first attempt at the 2026 Protocol was a disaster of biblical proportions. Thanks for reading Muchomota! Subscribe for free to…
-
The 2026 Protocol: Engineering Freedom (And The Market As A Mirror)
Date: December 29, 2025 Location: Unknown Detention Center, [REDACTED] Status: Critical Humidity Levels (No Sauna) Bankroll: $0 (Sam), $5,000 (Bob) It is late December. I am incarcerated in a facility that violates every human right known to the Nordic Council. Thanks for reading Muchomota! Subscribe for free to receive new posts and support my work.…